
By Kevin Petrie, Vice President of Research, Eckerson Group
In good times, data silos cause problems. In times of massive uncertainty, like now, silos kill companies.

Without integrated data, retailers cannot predict customer choices about in-store shopping. Manufacturers cannot plug holes in their supply chain, and healthcare providers cannot design COVID-19-resistant operations.
This is why there is no better time than the present to give serious consideration to convergence paradigms such as the data hub.
As with many terms, the meaning of “data hub” varies by vendor. Let’s define the data hub for this blog series as a platform that enables business managers and BI analysts to take a more hands-on role in data management and data governance. They can use the data hub to integrate, refine and explore data that spans customers, supply chains, employees, and other entities. They help glue things together with data governance, master data management (MDM), and data quality.

The data hub presents a pretty ambitious vision of data convergence. This blog series aims to help enterprises determine whether the data hub as defined here makes sense for their teams. This first blog examines the problem, the proposed solution, and its intended benefits. The second blog will assess the inherent tradeoffs of convergence and offer evaluation criteria to predict the impact of data hubs on enterprise environments. In the third blog, we will offer guiding principles for successful implementation.
Silo Symptoms

First, let’s drill down on the data silo problem. Perpetually starved for budget, IT organizations struggle with the technical debt of accumulated disparate systems. This creates inflexible, incomplete processes that delay projects, undermine compliance and prevent agile responses to changing business requirements.
Most enterprises experience the following symptoms to one degree or another. Those in severe pain should consider a data hub or other method of consolidation.
IT integrates tools, but not data. With each purchase of a best-of-breed tool, data and analytics teams increase the integration work required to make tools talk to each other. They have little time left to cleanse and transform data for operations or analytics.
Teams work at cross-purposes. Without central control, business managers in Sales, Finance, HR, and other business units build their own processes for expediency. Over time their datasets, formats, and processes drift apart. It becomes harder to share data, so teams only do it when they have to, relying on ad-hoc formats and methods rather than reusable templates.
Data stewards become firefighters. As independent business units go their own way, data stewards and other governance-related managers chase problems rather than preventing them. They spend too much time fixing data quality issues and correcting master data variations, and too little time implementing and enforcing enterprise policies.
Enter the Data Hub
The data hub seeks to break the silos by having business managers and BI analysts play a bigger role in data management and governance. They acquire, transform, cleanse and curate data to be explored. They assist compliance upfront with master data matching and data quality checks, rather than creating a mess for data stewards to clean up. As in any converging market segment, each data hub vendor tends to position its strongest capabilities as the central vantage point. Semarchy, for example, starts with MDM. Their xDM platform helps business managers assemble master data for myriad business parties – customers, employees, partners, etc. – so they can understand each party from all angles.
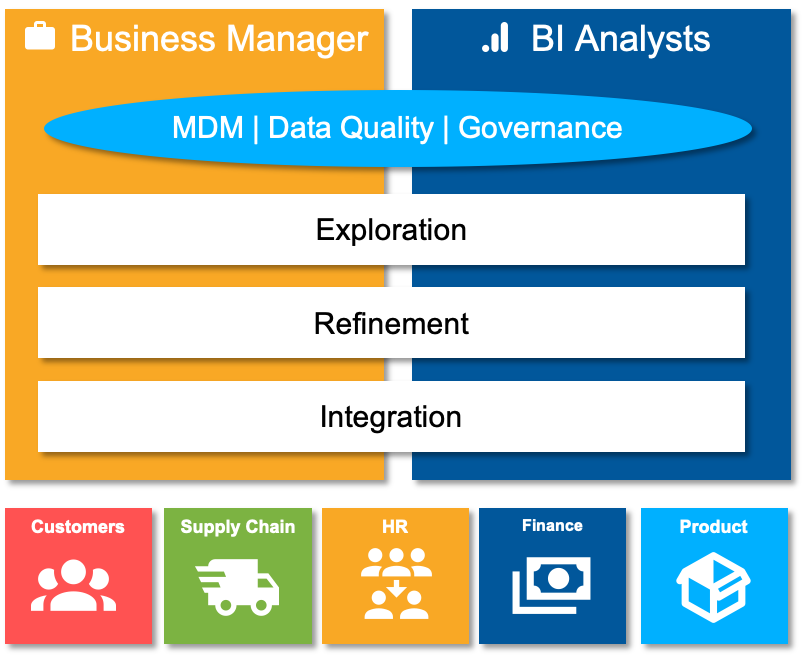
The following diagram illustrates the tasks that business managers and BI analysts help manage in this type of data hub.
Business managers. Marketing, HR, supply chain, or other managers use the data hub to assemble, reformat and explore data sets that drive their business functions, leveraging common templates within the graphical data hub interface. They identify master data gaps, then match and merge records. They visualize and therefore help govern the interrelationships of these parties using frameworks such as knowledge graphs.
BI analysts. Financial analysts and other BI users perform similar activities like those listed above, with newfound confidence in the quality of the data because it has been curated by business domain experts more than data engineers. With less transformation and preparation work, they find time to explore the data and potentially discover new insights – a critical opportunity in the fast-changing world of COVID-19.
And what about the data steward? They convert from firefighter to proactive governance officer, focusing on policy design and process efficiency improvement.
That’s the vision of the data hub. Our next blog puts the vision to the test of reality by weighing the pros of reinvention against the cons of change. To paraphrase Jeff Bezos, “the plan won’t survive its first encounters with reality.”